পূর্ণসংখ্যা ফ্যাক্টরাইজেশন#
এই আর্টিকেলে আমরা পূর্ণসংখ্যার ফ্যাক্টরাইজেশনের কয়েকটি অ্যালগরিদম তালিকাভুক্ত করব, যেগুলোর প্রতিটি ইনপুটের উপর নির্ভর করে দ্রুত অথবা বিভিন্ন স্তরে ধীর হতে পারে।
লক্ষ্য করুন, আপনি যে সংখ্যাটি ফ্যাক্টরাইজ করতে চান সেটি আসলে একটি মৌলিক সংখ্যা হলে, বেশিরভাগ অ্যালগরিদম অত্যন্ত ধীরে চলবে। এটি বিশেষ করে ফের্মার, পোলার্ডের p-1 এবং পোলার্ডের রো ফ্যাক্টরাইজেশন অ্যালগরিদমের জন্য সত্য। তাই, সংখ্যাটি ফ্যাক্টরাইজ করার চেষ্টা করার আগে একটি প্রোবাবিলিস্টিক (অথবা দ্রুত ডিটারমিনিস্টিক) প্রাইমালিটি টেস্ট সম্পাদন করা সবচেয়ে যুক্তিসঙ্গত।
ট্রায়াল ডিভিশন#
এটি মৌলিক উৎপাদক বিভাজন খুঁজে বের করার সবচেয়ে মৌলিক অ্যালগরিদম।
আমরা প্রতিটি সম্ভাব্য ভাজক $d$ দ্বারা ভাগ করি। লক্ষ্য করা যায় যে একটি যৌগিক সংখ্যা $n$-এর সকল মৌলিক গুণনীয়ক $\sqrt{n}$-এর চেয়ে বড় হওয়া অসম্ভব। তাই, আমাদের শুধু $2 \le d \le \sqrt{n}$ ভাজকগুলো পরীক্ষা করতে হবে, যা $O(\sqrt{n})$-এ মৌলিক উৎপাদক বিভাজন দেয়। (এটি সিউডো-পলিনোমিয়াল টাইম, অর্থাৎ ইনপুটের মানের পলিনোমিয়াল কিন্তু ইনপুটের বিটের সংখ্যার এক্সপোনেনশিয়াল।)
ক্ষুদ্রতম ভাজকটি অবশ্যই একটি মৌলিক সংখ্যা। আমরা ফ্যাক্টর করা সংখ্যাটি সরিয়ে ফেলি, এবং প্রক্রিয়া চালিয়ে যাই। $[2; \sqrt{n}]$ রেঞ্জে কোনো ভাজক খুঁজে পাওয়া না গেলে, সংখ্যাটি নিজেই মৌলিক।
vector<long long> trial_division1(long long n) {
vector<long long> factorization;
for (long long d = 2; d * d <= n; d++) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}হুইল ফ্যাক্টরাইজেশন#
এটি ট্রায়াল ডিভিশনের একটি অপটিমাইজেশন। একবার জানা গেলে যে সংখ্যাটি ২ দ্বারা বিভাজ্য নয়, আমাদের অন্য জোড় সংখ্যা পরীক্ষা করার দরকার নেই। এতে পরীক্ষা করার সংখ্যা $50\%$ থাকে। ২ ফ্যাক্টর করে বের করার পর, একটি বিজোড় সংখ্যা পেয়ে, আমরা কেবল ৩ থেকে শুরু করতে পারি এবং শুধু বিজোড় সংখ্যাগুলো গণনা করতে পারি।
vector<long long> trial_division2(long long n) {
vector<long long> factorization;
while (n % 2 == 0) {
factorization.push_back(2);
n /= 2;
}
for (long long d = 3; d * d <= n; d += 2) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}এই পদ্ধতিটি আরও সম্প্রসারিত করা যায়। সংখ্যাটি ৩ দ্বারা বিভাজ্য না হলে, ভবিষ্যতের গণনায় ৩-এর সকল গুণিতকও উপেক্ষা করা যায়। তাই আমাদের শুধু $5, 7, 11, 13, 17, 19, 23, \dots$ সংখ্যাগুলো পরীক্ষা করতে হবে। আমরা এই অবশিষ্ট সংখ্যাগুলোর একটি প্যাটার্ন দেখতে পাই। আমাদের $d \bmod 6 = 1$ এবং $d \bmod 6 = 5$ সহ সকল সংখ্যা পরীক্ষা করতে হবে। তাই এতে পরীক্ষা করার সংখ্যা $33.3\%$ থাকে। আমরা প্রথমে ২ এবং ৩ মৌলিক সংখ্যাগুলো ফ্যাক্টর করে বের করে এটি ইমপ্লিমেন্ট করতে পারি, তারপর ৫ থেকে শুরু করে ৬ মডুলোতে ভাগশেষ $1$ এবং $5$ গণনা করতে পারি।
এখানে মৌলিক সংখ্যা ২, ৩ এবং ৫-এর জন্য একটি ইমপ্লিমেন্টেশন দেওয়া হলো। স্কিপিং স্ট্রাইডগুলো একটি অ্যারেতে সংরক্ষণ করা সুবিধাজনক।
vector<long long> trial_division3(long long n) {
vector<long long> factorization;
for (int d : {2, 3, 5}) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
static array<int, 8> increments = {4, 2, 4, 2, 4, 6, 2, 6};
int i = 0;
for (long long d = 7; d * d <= n; d += increments[i++]) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
if (i == 8)
i = 0;
}
if (n > 1)
factorization.push_back(n);
return factorization;
}আমরা যদি এই পদ্ধতিটি আরও মৌলিক সংখ্যা অন্তর্ভুক্ত করতে সম্প্রসারিত করতে থাকি, আরও ভালো শতাংশ অর্জন করা যায়, তবে স্কিপ লিস্ট বড় হয়ে যাবে।
প্রিকম্পিউটেড প্রাইম#
হুইল ফ্যাক্টরাইজেশন পদ্ধতিটি অনির্দিষ্টভাবে সম্প্রসারিত করলে, পরীক্ষা করার জন্য শুধু মৌলিক সংখ্যাগুলোই থাকবে। এটি পরীক্ষা করার একটি ভালো উপায় হলো $\sqrt{n}$ পর্যন্ত সকল মৌলিক সংখ্যা ইরাতোস্থেনিসের চালুনি দিয়ে প্রিকম্পিউট করা, এবং সেগুলো পৃথকভাবে পরীক্ষা করা।
vector<long long> primes;
vector<long long> trial_division4(long long n) {
vector<long long> factorization;
for (long long d : primes) {
if (d * d > n)
break;
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}ফের্মার ফ্যাক্টরাইজেশন পদ্ধতি#
আমরা একটি বিজোড় যৌগিক সংখ্যা $n = p \cdot q$ কে দুটি বর্গের পার্থক্য হিসেবে লিখতে পারি $n = a^2 - b^2$:
$$n = \left(\frac{p + q}{2}\right)^2 - \left(\frac{p - q}{2}\right)^2$$ফের্মার ফ্যাক্টরাইজেশন পদ্ধতি এই তথ্যটি কাজে লাগানোর চেষ্টা করে প্রথম বর্গ $a^2$ অনুমান করে, এবং অবশিষ্ট অংশ $b^2 = a^2 - n$ একটি পূর্ণবর্গ সংখ্যা কিনা পরীক্ষা করে। যদি হয়, তাহলে আমরা $n$-এর গুণনীয়ক $a - b$ এবং $a + b$ খুঁজে পেয়েছি।
int fermat(int n) {
int a = ceil(sqrt(n));
int b2 = a*a - n;
int b = round(sqrt(b2));
while (b * b != b2) {
a = a + 1;
b2 = a*a - n;
b = round(sqrt(b2));
}
return a - b;
}দুটি গুণনীয়ক $p$ এবং $q$-এর পার্থক্য ছোট হলে এই ফ্যাক্টরাইজেশন পদ্ধতি অত্যন্ত দ্রুত হতে পারে। অ্যালগরিদমটি $O(|p - q|)$ সময়ে চলে। তবে প্র্যাকটিসে, এই পদ্ধতি খুব কমই ব্যবহৃত হয়। গুণনীয়কগুলো দূরে সরে গেলে, এটি অত্যন্ত ধীর।
তবে, এই পদ্ধতি সংক্রান্ত এখনও বিপুল সংখ্যক অপটিমাইজেশন বিকল্প আছে। একটি নির্দিষ্ট ছোট সংখ্যা মডুলোতে $a^2$ বর্গগুলো দেখলে, লক্ষ্য করা যায় যে কিছু নির্দিষ্ট মান $a$ দেখার দরকার নেই, কারণ তারা $a^2 - n$ পূর্ণবর্গ সংখ্যা তৈরি করতে পারে না।
পোলার্ডের $p - 1$ পদ্ধতি#
এটি অত্যন্ত সম্ভাবনাময় যে একটি সংখ্যা $n$-এর অন্তত একটি মৌলিক গুণনীয়ক $p$ আছে যেন $p - 1$ ছোট $\mathrm{B}$-এর জন্য $\mathrm{B}$-পাওয়ারস্মুথ। একটি পূর্ণসংখ্যা $m$-কে $\mathrm{B}$-পাওয়ারস্মুথ বলা হয় যদি $m$-কে ভাগ করে এমন প্রতিটি মৌলিক ঘাত সর্বাধিক $\mathrm{B}$ হয়। আনুষ্ঠানিকভাবে, ধরি $\mathrm{B} \geqslant 1$ এবং $m$ যেকোনো ধনাত্মক পূর্ণসংখ্যা। ধরুন $m$-এর মৌলিক উৎপাদক বিভাজন $m = \prod {q_i}^{e_i}$, যেখানে প্রতিটি $q_i$ মৌলিক এবং $e_i \geqslant 1$। তাহলে $m$ $\mathrm{B}$-পাওয়ারস্মুথ যদি, সকল $i$-এর জন্য, ${q_i}^{e_i} \leqslant \mathrm{B}$। যেমন $4817191$-এর মৌলিক উৎপাদক বিভাজন $1303 \cdot 3697$। এবং $1303 - 1$ ও $3697 - 1$-এর মানগুলো যথাক্রমে $31$-পাওয়ারস্মুথ এবং $16$-পাওয়ারস্মুথ, কারণ $1303 - 1 = 2 \cdot 3 \cdot 7 \cdot 31$ এবং $3697 - 1 = 2^4 \cdot 3 \cdot 7 \cdot 11$। ১৯৭৪ সালে জন পোলার্ড একটি যৌগিক সংখ্যা থেকে এমন গুণনীয়ক $p$ বের করার একটি পদ্ধতি আবিষ্কার করেন, যেখানে $p-1$ হলো $\mathrm{B}$-পাওয়ারস্মুথ।
ধারণাটি আসে ফের্মার ক্ষুদ্র উপপাদ্য থেকে। ধরি $n$-এর ফ্যাক্টরাইজেশন $n = p \cdot q$। এটি বলে যে $a$ যদি $p$-এর সহমৌলিক হয়, তাহলে নিম্নলিখিত উক্তি ধরে:
$$a^{p - 1} \equiv 1 \pmod{p}$$এটি এও মানে
$${\left(a^{(p - 1)}\right)}^k \equiv a^{k \cdot (p - 1)} \equiv 1 \pmod{p}.$$তাই $p - 1 ~|~ M$ হলে যেকোনো $M$-এর জন্য আমরা জানি $a^M \equiv 1$। এর মানে $a^M - 1 = p \cdot r$, এবং সেই কারণে $p ~|~ \gcd(a^M - 1, n)$।
তাই, যদি $n$-এর কোনো গুণনীয়ক $p$-এর জন্য $p - 1$ $M$-কে ভাগ করে, আমরা ইউক্লিডের অ্যালগরিদম ব্যবহার করে একটি গুণনীয়ক বের করতে পারি।
এটি স্পষ্ট যে, প্রতিটি $\mathrm{B}$-পাওয়ারস্মুথ সংখ্যার গুণিতক সর্বনিম্ন $M$ হলো $\text{lcm}(1,~2~,3~,4~,~\dots,~B)$। বিকল্পভাবে:
$$M = \prod_{\text{prime } q \le B} q^{\lfloor \log_q B \rfloor}$$লক্ষ্য করুন, $n$-এর সকল মৌলিক গুণনীয়ক $p$-এর জন্য $p-1$ যদি $M$-কে ভাগ করে, তাহলে $\gcd(a^M - 1, n)$ কেবল $n$ হবে। এই ক্ষেত্রে আমরা কোনো গুণনীয়ক পাই না। তাই, আমরা $M$ গণনা করার সময় একাধিকবার $\gcd$ সম্পাদন করার চেষ্টা করব।
কিছু যৌগিক সংখ্যার এমন কোনো গুণনীয়ক $p$ নেই যেন $p-1$ ছোট $\mathrm{B}$-এর জন্য $\mathrm{B}$-পাওয়ারস্মুথ। উদাহরণস্বরূপ, যৌগিক সংখ্যা $100~000~000~000~000~493 = 763~013 \cdot 131~059~365~961$-এর জন্য, $p-1$ এর মানগুলো যথাক্রমে $190~753$-পাওয়ারস্মুথ এবং $1~092~161~383$-পাওয়ারস্মুথ। সংখ্যাটি ফ্যাক্টরাইজ করতে আমাদের $B \geq 190~753$ বেছে নিতে হবে।
নিম্নলিখিত ইমপ্লিমেন্টেশনে আমরা $\mathrm{B} = 10$ দিয়ে শুরু করি এবং প্রতিটি ইটারেশনের পরে $\mathrm{B}$ বৃদ্ধি করি।
long long pollards_p_minus_1(long long n) {
int B = 10;
long long g = 1;
while (B <= 1000000 && g < n) {
long long a = 2 + rand() % (n - 3);
g = gcd(a, n);
if (g > 1)
return g;
// compute a^M
for (int p : primes) {
if (p >= B)
continue;
long long p_power = 1;
while (p_power * p <= B)
p_power *= p;
a = power(a, p_power, n);
g = gcd(a - 1, n);
if (g > 1 && g < n)
return g;
}
B *= 2;
}
return 1;
}লক্ষ্য করুন যে এটি একটি প্রোবাবিলিস্টিক অ্যালগরিদম। এর একটি পরিণতি হলো অ্যালগরিদম কোনো গুণনীয়ক খুঁজে পাওয়ার ব্যর্থ হওয়ার সম্ভাবনা আছে।
কমপ্লেক্সিটি প্রতি ইটারেশনে $O(B \log B \log^2 n)$।
পোলার্ডের রো অ্যালগরিদম#
পোলার্ডের রো অ্যালগরিদম জন পোলার্ডের আরেকটি ফ্যাক্টরাইজেশন অ্যালগরিদম।
ধরি একটি সংখ্যার মৌলিক উৎপাদক বিভাজন $n = p q$। অ্যালগরিদমটি একটি সিউডো-র্যান্ডম সিকোয়েন্স $\{x_i\} = \{x_0,~f(x_0),~f(f(x_0)),~\dots\}$ দেখে যেখানে $f$ একটি পলিনোমিয়াল ফাংশন, সাধারণত $f(x) = (x^2 + c) \bmod n$ বেছে নেওয়া হয় $c = 1$ সহ।
এই ক্ষেত্রে, আমরা সিকোয়েন্স $\{x_i\}$-এ আগ্রহী নই। আমরা সিকোয়েন্স $\{x_i \bmod p\}$-এ বেশি আগ্রহী। যেহেতু $f$ একটি পলিনোমিয়াল ফাংশন, এবং সকল মান $[0;~p)$ রেঞ্জে, এই সিকোয়েন্স অবশেষে একটি লুপে রূপান্তরিত হবে। বার্থডে প্যারাডক্স আসলে বলে যে পুনরাবৃত্তি শুরু হওয়ার আগে প্রত্যাশিত উপাদানের সংখ্যা $O(\sqrt{p})$। যদি $p$ $\sqrt{n}$-এর চেয়ে ছোট হয়, পুনরাবৃত্তি সম্ভবত $O(\sqrt[4]{n})$-এ শুরু হবে।
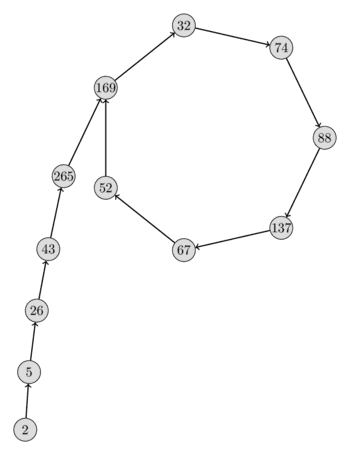
এখানে $n = 2206637$, $p = 317$, $x_0 = 2$ এবং $f(x) = x^2 + 1$ সহ এমন একটি সিকোয়েন্স $\{x_i \bmod p\}$-এর ভিজুয়ালাইজেশন দেওয়া হলো। সিকোয়েন্সের আকৃতি থেকে আপনি স্পষ্টভাবে দেখতে পারেন কেন অ্যালগরিদমটিকে পোলার্ডের $\rho$ অ্যালগরিদম বলা হয়।
তবুও, একটি খোলা প্রশ্ন আছে। $p$ সংখ্যাটি না জেনেই কীভাবে আমরা সিকোয়েন্স $\{x_i \bmod p\}$-এর বৈশিষ্ট্যগুলো আমাদের সুবিধায় কাজে লাগাতে পারি?
এটি আসলে বেশ সহজ। সিকোয়েন্স $\{x_i \bmod p\}_{i \le j}$-এ একটি সাইকেল আছে যদি এবং কেবল যদি দুটি ইনডেক্স $s, t \le j$ থাকে যেন $x_s \equiv x_t \bmod p$। এই সমীকরণটি $x_s - x_t \equiv 0 \bmod p$ হিসেবে পুনরায় লেখা যায় যা $p ~|~ \gcd(x_s - x_t, n)$-এর সমান।
তাই, যদি আমরা $g = \gcd(x_s - x_t, n) > 1$ সহ দুটি ইনডেক্স $s$ ও $t$ খুঁজে পাই, আমরা একটি সাইকেল এবং $n$-এর একটি গুণনীয়ক $g$ উভয়ই পেয়েছি। $g = n$ হওয়া সম্ভব। সেক্ষেত্রে আমরা কোনো সঠিক গুণনীয়ক পাইনি, তাই ভিন্ন প্যারামিটার দিয়ে (ভিন্ন শুরুর মান $x_0$, পলিনোমিয়াল ফাংশন $f$-এ ভিন্ন ধ্রুবক $c$) প্রক্রিয়াটি পুনরাবৃত্তি করতে হবে।
সাইকেল খুঁজে পেতে, আমরা যেকোনো সাধারণ সাইকেল ডিটেকশন অ্যালগরিদম ব্যবহার করতে পারি।
ফ্লয়ডের সাইকেল-ফাইন্ডিং অ্যালগরিদম#
এই অ্যালগরিদম ভিন্ন গতিতে সিকোয়েন্সের মধ্য দিয়ে চলমান দুটি পয়েন্টার ব্যবহার করে একটি সাইকেল খুঁজে বের করে। প্রতিটি ইটারেশনে, প্রথম পয়েন্টারটি একটি উপাদান এগিয়ে যায়, আর দ্বিতীয় পয়েন্টারটি প্রতি অন্য উপাদানে এগিয়ে যায়। এই ধারণা ব্যবহার করে দেখা সহজ যে সাইকেল থাকলে, কোনো একটি সময়ে দ্বিতীয় পয়েন্টারটি লুপের সময় প্রথমটির সাথে দেখা করবে। সাইকেলের দৈর্ঘ্য $\lambda$ এবং সাইকেল শুরু হওয়ার প্রথম ইনডেক্স $\mu$ হলে, অ্যালগরিদমটি $O(\lambda + \mu)$ সময়ে চলবে।
এই অ্যালগরিদমটি টরটয়েজ অ্যান্ড হেয়ার অ্যালগরিদম নামেও পরিচিত, কচ্ছপ (ধীর পয়েন্টার) এবং খরগোশের (দ্রুত পয়েন্টার) দৌড়ের গল্পের উপর ভিত্তি করে।
এই অ্যালগরিদম ব্যবহার করে $\lambda$ এবং $\mu$ প্যারামিটার নির্ধারণ করাও সম্ভব ($O(\lambda + \mu)$ সময়ে এবং $O(1)$ স্পেসে)। সাইকেল সনাক্ত হলে, অ্যালগরিদম ‘True’ রিটার্ন করবে। সিকোয়েন্সে সাইকেল না থাকলে, ফাংশনটি অনির্দিষ্টকালের জন্য লুপ করবে। তবে, পোলার্ডের রো অ্যালগরিদম ব্যবহার করে এটি প্রতিরোধ করা যায়।
function floyd(f, x0):
tortoise = x0
hare = f(x0)
while tortoise != hare:
tortoise = f(tortoise)
hare = f(f(hare))
return trueইমপ্লিমেন্টেশন#
প্রথমে, ফ্লয়ডের সাইকেল-ফাইন্ডিং অ্যালগরিদম ব্যবহার করে একটি ইমপ্লিমেন্টেশন দেওয়া হলো। অ্যালগরিদমটি সাধারণত $O(\sqrt[4]{n} \log(n))$ সময়ে চলে।
long long mult(long long a, long long b, long long mod) {
return (__int128)a * b % mod;
}
long long f(long long x, long long c, long long mod) {
return (mult(x, x, mod) + c) % mod;
}
long long rho(long long n, long long x0=2, long long c=1) {
long long x = x0;
long long y = x0;
long long g = 1;
while (g == 1) {
x = f(x, c, n);
y = f(y, c, n);
y = f(y, c, n);
g = gcd(abs(x - y), n);
}
return g;
}নিম্নলিখিত টেবিলটি $n = 2206637$, $x_0 = 2$ এবং $c = 1$-এর জন্য অ্যালগরিদমের সময় $x$ ও $y$-এর মান দেখায়।
$$ \newcommand\T{\Rule{0pt}{1em}{.3em}} \begin{array}{|l|l|l|l|l|l|} \hline i & x_i \bmod n & x_{2i} \bmod n & x_i \bmod 317 & x_{2i} \bmod 317 & \gcd(x_i - x_{2i}, n) \\ \hline 0 & 2 & 2 & 2 & 2 & - \\ 1 & 5 & 26 & 5 & 26 & 1 \\ 2 & 26 & 458330 & 26 & 265 & 1 \\ 3 & 677 & 1671573 & 43 & 32 & 1 \\ 4 & 458330 & 641379 & 265 & 88 & 1 \\ 5 & 1166412 & 351937 & 169 & 67 & 1 \\ 6 & 1671573 & 1264682 & 32 & 169 & 1 \\ 7 & 2193080 & 2088470 & 74 & 74 & 317 \\ \hline \end{array}$$ইমপ্লিমেন্টেশনটি একটি mult ফাংশন ব্যবহার করে, যা $\le 10^{18}$ দুটি পূর্ণসংখ্যা ওভারফ্লো ছাড়াই গুণ করে GCC-এর ১২৮-বিট ইন্টিজারের জন্য __int128 টাইপ ব্যবহার করে।
GCC পাওয়া না গেলে, আপনি বাইনারি এক্সপোনেনশিয়েশনের অনুরূপ একটি ধারণা ব্যবহার করতে পারেন।
long long mult(long long a, long long b, long long mod) {
long long result = 0;
while (b) {
if (b & 1)
result = (result + a) % mod;
a = (a + a) % mod;
b >>= 1;
}
return result;
}বিকল্পভাবে আপনি মন্টগোমারি মাল্টিপ্লিকেশনও ইমপ্লিমেন্ট করতে পারেন।
পূর্বে বলা হয়েছে, $n$ যৌগিক হলে এবং অ্যালগরিদম $n$-কে গুণনীয়ক হিসেবে রিটার্ন করলে, আপনাকে ভিন্ন প্যারামিটার $x_0$ ও $c$ দিয়ে প্রক্রিয়াটি পুনরাবৃত্তি করতে হবে। যেমন $x_0 = c = 1$ বেছে নিলে $25 = 5 \cdot 5$ ফ্যাক্টরাইজ করবে না। অ্যালগরিদম $25$ রিটার্ন করবে। তবে, $x_0 = 1$, $c = 2$ বেছে নিলে এটি ফ্যাক্টরাইজ করবে।
ব্রেন্টের অ্যালগরিদম#
ব্রেন্ট ফ্লয়ডের অনুরূপ একটি পদ্ধতি ইমপ্লিমেন্ট করেন, দুটি পয়েন্টার ব্যবহার করে। পার্থক্য হলো পয়েন্টারগুলো যথাক্রমে এক ও দুই স্থান এগিয়ে যাওয়ার পরিবর্তে, ২-এর ঘাত দ্বারা এগিয়ে যায়। $2^i$ $\lambda$ এবং $\mu$-এর চেয়ে বড় হলেই, আমরা সাইকেল খুঁজে পাব।
function floyd(f, x0):
tortoise = x0
hare = f(x0)
l = 1
while tortoise != hare:
tortoise = hare
repeat l times:
hare = f(hare)
if tortoise == hare:
return true
l *= 2
return trueব্রেন্টের অ্যালগরিদমও রৈখিক সময়ে চলে, তবে সাধারণত ফ্লয়ডের চেয়ে দ্রুত, কারণ এটি ফাংশন $f$-এর কম ইভ্যালুয়েশন ব্যবহার করে।
ইমপ্লিমেন্টেশন#
ব্রেন্টের অ্যালগরিদমের সোজাসুজি ইমপ্লিমেন্টেশন $x_l - x_k$ পদগুলো $k < \frac{3 \cdot l}{2}$ হলে বাদ দিয়ে দ্রুত করা যায়। এছাড়াও, প্রতি ধাপে $\gcd$ গণনা করার পরিবর্তে, আমরা পদগুলো গুণ করি এবং আসলে কয়েক ধাপ পরপর $\gcd$ পরীক্ষা করি এবং অতিক্রম করলে পেছনে ফিরে যাই।
long long brent(long long n, long long x0=2, long long c=1) {
long long x = x0;
long long g = 1;
long long q = 1;
long long xs, y;
int m = 128;
int l = 1;
while (g == 1) {
y = x;
for (int i = 1; i < l; i++)
x = f(x, c, n);
int k = 0;
while (k < l && g == 1) {
xs = x;
for (int i = 0; i < m && i < l - k; i++) {
x = f(x, c, n);
q = mult(q, abs(y - x), n);
}
g = gcd(q, n);
k += m;
}
l *= 2;
}
if (g == n) {
do {
xs = f(xs, c, n);
g = gcd(abs(xs - y), n);
} while (g == 1);
}
return g;
}ছোট মৌলিক সংখ্যাগুলোর জন্য ট্রায়াল ডিভিশনের সাথে পোলার্ডের রো অ্যালগরিদমের ব্রেন্ট ভার্সনের সমন্বয় একটি অত্যন্ত শক্তিশালী ফ্যাক্টরাইজেশন অ্যালগরিদম তৈরি করে।