এরাটোস্থেনিসের সিভ#
এরাটোস্থেনিসের সিভ হলো একটি অ্যালগরিদম যা $O(n \log \log n)$ অপারেশন ব্যবহার করে $[1;n]$ সেগমেন্টের সকল মৌলিক সংখ্যা খুঁজে বের করে।
অ্যালগরিদমটি অত্যন্ত সরল: শুরুতে আমরা ২ থেকে $n$ পর্যন্ত সকল সংখ্যা লিখে রাখি। আমরা ২-এর সকল প্রকৃত গুণিতককে (যেহেতু ২ হলো ক্ষুদ্রতম মৌলিক সংখ্যা) যৌগিক সংখ্যা হিসেবে চিহ্নিত করি। একটি সংখ্যা $x$-এর প্রকৃত গুণিতক হলো এমন একটি সংখ্যা যা $x$-এর চেয়ে বড় এবং $x$ দ্বারা বিভাজ্য। এরপর আমরা পরবর্তী যে সংখ্যাটি যৌগিক হিসেবে চিহ্নিত হয়নি সেটি খুঁজে বের করি, এক্ষেত্রে সেটি হলো ৩। অর্থাৎ ৩ একটি মৌলিক সংখ্যা, এবং আমরা ৩-এর সকল প্রকৃত গুণিতককে যৌগিক হিসেবে চিহ্নিত করি। পরবর্তী অচিহ্নিত সংখ্যা হলো ৫, যা পরবর্তী মৌলিক সংখ্যা, এবং আমরা এর সকল প্রকৃত গুণিতক চিহ্নিত করি। সারির সকল সংখ্যা প্রক্রিয়া না করা পর্যন্ত আমরা এই পদ্ধতি চালিয়ে যাই।
নিচের চিত্রে $[1; 16]$ পরিসরে সকল মৌলিক সংখ্যা নির্ণয়ের জন্য অ্যালগরিদমটির একটি ভিজ্যুয়ালাইজেশন দেখতে পাবেন। দেখা যাচ্ছে যে, প্রায়ই আমরা সংখ্যাগুলোকে একাধিকবার যৌগিক হিসেবে চিহ্নিত করি।
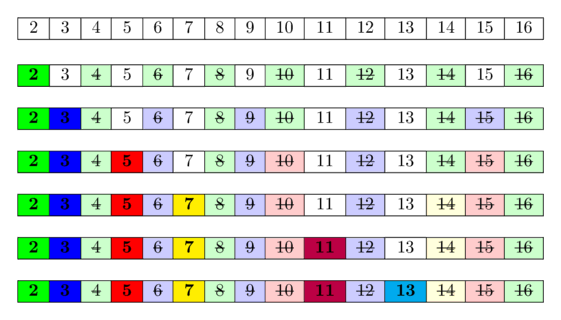
এর পেছনের মূল ধারণা হলো: একটি সংখ্যা মৌলিক, যদি এর চেয়ে ছোট কোনো মৌলিক সংখ্যা এটিকে ভাগ করতে না পারে। যেহেতু আমরা মৌলিক সংখ্যাগুলো ক্রমানুসারে ইটারেট করছি, তাই যেসব সংখ্যা কমপক্ষে একটি মৌলিক সংখ্যা দ্বারা বিভাজ্য, সেগুলোকে আমরা ইতিমধ্যেই বিভাজ্য হিসেবে চিহ্নিত করে ফেলেছি। সুতরাং, আমরা যখন একটি ঘরে পৌঁছাই এবং সেটি চিহ্নিত না থাকে, তাহলে এটি কোনো ছোট মৌলিক সংখ্যা দ্বারা বিভাজ্য নয় এবং তাই এটি অবশ্যই মৌলিক।
ইমপ্লিমেন্টেশন#
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; i++) {
if (is_prime[i] && (long long)i * i <= n) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}এই কোডটি প্রথমে শূন্য এবং এক ব্যতীত সকল সংখ্যাকে সম্ভাব্য মৌলিক সংখ্যা হিসেবে চিহ্নিত করে, তারপর যৌগিক সংখ্যা ছাঁকনির প্রক্রিয়া শুরু করে।
এর জন্য এটি $2$ থেকে $n$ পর্যন্ত সকল সংখ্যার উপর ইটারেট করে।
বর্তমান সংখ্যা $i$ যদি মৌলিক সংখ্যা হয়, তাহলে এটি $i^2$ থেকে শুরু করে $i$-এর সকল গুণিতককে যৌগিক সংখ্যা হিসেবে চিহ্নিত করে।
এটি ইতিমধ্যেই সাধারণ ইমপ্লিমেন্টেশনের তুলনায় একটি অপটিমাইজেশন, এবং এটি সম্ভব কারণ $i$-এর গুণিতক যেসব ছোট সংখ্যা আছে সেগুলোর অবশ্যই $i$-এর চেয়ে ছোট একটি মৌলিক গুণনীয়ক রয়েছে, তাই সেগুলো আগেই ছাঁকা হয়ে গেছে।
যেহেতু $i^2$ সহজেই int টাইপ ওভারফ্লো করতে পারে, তাই দ্বিতীয় নেস্টেড লুপের আগে long long টাইপ ব্যবহার করে অতিরিক্ত যাচাই করা হয়।
এই ইমপ্লিমেন্টেশন ব্যবহার করলে অ্যালগরিদমটি $O(n)$ মেমোরি ব্যবহার করে (যা স্পষ্টতই) এবং $O(n \log \log n)$ অপারেশন সম্পাদন করে (পরবর্তী বিভাগ দেখুন)।
অ্যাসিম্পটোটিক অ্যানালাইসিস#
মৌলিক সংখ্যার বিতরণ সম্পর্কে কিছু না জেনেও $O(n \log n)$ রানিং টাইম প্রমাণ করা সহজ — is_prime চেক উপেক্ষা করলে, ভেতরের লুপটি $i = 2, 3, 4, \dots$-এর জন্য (সর্বোচ্চ) $n/i$ বার চলে, যার ফলে ভেতরের লুপে মোট অপারেশনের সংখ্যা একটি হারমোনিক সিরিজের মতো হয় যেমন $n(1/2 + 1/3 + 1/4 + \cdots)$, যা $O(n \log n)$ দ্বারা সীমাবদ্ধ।
এবার প্রমাণ করা যাক যে অ্যালগরিদমের রানিং টাইম হলো $O(n \log \log n)$। ভেতরের লুপে অ্যালগরিদমটি প্রতিটি মৌলিক সংখ্যা $p \le n$-এর জন্য $\frac{n}{p}$ অপারেশন সম্পাদন করবে। সুতরাং, আমাদের নিচের রাশিটি মূল্যায়ন করতে হবে:
$$\sum_{\substack{p \le n, \\\ p \text{ prime}}} \frac n p = n \cdot \sum_{\substack{p \le n, \\\ p \text{ prime}}} \frac 1 p.$$দুটি পরিচিত তথ্য স্মরণ করা যাক।
- $n$-এর চেয়ে ছোট বা সমান মৌলিক সংখ্যার সংখ্যা আনুমানিক $\frac n {\ln n}$।
- $k$-তম মৌলিক সংখ্যা আনুমানিক $k \ln k$-এর সমান (এটি পূর্ববর্তী তথ্য থেকে অনুমিত)।
সুতরাং আমরা যোগফলটি নিচের মতো লিখতে পারি:
$$\sum_{\substack{p \le n, \\\ p \text{ prime}}} \frac 1 p \approx \frac 1 2 + \sum_{k = 2}^{\frac n {\ln n}} \frac 1 {k \ln k}.$$এখানে আমরা প্রথম মৌলিক সংখ্যা ২-কে যোগফল থেকে আলাদা করেছি, কারণ $k = 1$ এর ক্ষেত্রে $k \ln k$-এর আসন্ন মান $0$ হয় এবং শূন্য দিয়ে ভাগের সমস্যা তৈরি করে।
এখন, $k$-এর উপর $2$ থেকে $\frac n {\ln n}$ পর্যন্ত একই ফাংশনের ইন্টিগ্রাল ব্যবহার করে এই যোগফল মূল্যায়ন করা যাক (আমরা এই আসন্নীকরণ করতে পারি কারণ, প্রকৃতপক্ষে, যোগফলটি আয়তক্ষেত্র পদ্ধতি ব্যবহার করে ইন্টিগ্রালের আসন্ন মানের সাথে সম্পর্কিত):
$$\sum_{k = 2}^{\frac n {\ln n}} \frac 1 {k \ln k} \approx \int_2^{\frac n {\ln n}} \frac 1 {k \ln k} dk.$$ইন্টিগ্র্যান্ডের অ্যান্টিডেরিভেটিভ হলো $\ln \ln k$। প্রতিস্থাপন ব্যবহার করে এবং নিম্নতর ক্রমের পদগুলো সরিয়ে, আমরা ফলাফল পাব:
$$\int_2^{\frac n {\ln n}} \frac 1 {k \ln k} dk = \ln \ln \frac n {\ln n} - \ln \ln 2 = \ln(\ln n - \ln \ln n) - \ln \ln 2 \approx \ln \ln n.$$এখন, মূল যোগফলে ফিরে গেলে, আমরা এর আনুমানিক মূল্যায়ন পাব:
$$\sum_{\substack{p \le n, \\\ p\ is\ prime}} \frac n p \approx n \ln \ln n + o(n).$$আরও কঠোর প্রমাণ (যা ধ্রুবক গুণকের মধ্যে আরও সুনির্দিষ্ট মূল্যায়ন দেয়) Hardy ও Wright রচিত “An Introduction to the Theory of Numbers” গ্রন্থে (পৃ. ৩৪৯) পাওয়া যাবে।
এরাটোস্থেনিসের সিভের বিভিন্ন অপটিমাইজেশন#
অ্যালগরিদমটির সবচেয়ে বড় দুর্বলতা হলো, এটি মেমোরিতে একাধিকবার “হেঁটে” যায় এবং প্রতিবার শুধুমাত্র একক উপাদান পরিবর্তন করে। এটি খুব বেশি ক্যাশ-ফ্রেন্ডলি নয়। এবং এই কারণে, $O(n \log \log n)$-এর মধ্যে লুকানো ধ্রুবকটি তুলনামূলকভাবে বড়।
তাছাড়া, বড় $n$-এর জন্য ব্যবহৃত মেমোরি একটি বটলনেক হয়ে দাঁড়ায়।
নিচে উপস্থাপিত পদ্ধতিগুলো আমাদেরকে সম্পাদিত অপারেশনের পরিমাণ কমাতে এবং ব্যবহৃত মেমোরি উল্লেখযোগ্যভাবে হ্রাস করতে সাহায্য করে।
বর্গমূল পর্যন্ত সিভিং#
স্পষ্টতই, $n$ পর্যন্ত সকল মৌলিক সংখ্যা খুঁজে বের করতে, শুধুমাত্র $n$-এর বর্গমূলের বেশি নয় এমন মৌলিক সংখ্যা দিয়ে ছাঁকনি চালানোই যথেষ্ট।
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i * i <= n; i++) {
if (is_prime[i]) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}এই অপটিমাইজেশন কমপ্লেক্সিটিকে প্রভাবিত করে না (প্রকৃতপক্ষে, উপরে উপস্থাপিত প্রমাণটি পুনরাবৃত্তি করলে আমরা $n \ln \ln \sqrt n + o(n)$ মূল্যায়ন পাব, যা লগারিদমের বৈশিষ্ট্য অনুসারে অ্যাসিম্পটোটিকভাবে একই), তবে অপারেশনের সংখ্যা উল্লেখযোগ্যভাবে হ্রাস পাবে।
শুধুমাত্র বিজোড় সংখ্যা দিয়ে সিভিং#
যেহেতু সকল জোড় সংখ্যা (২ ব্যতীত) যৌগিক, তাই আমরা জোড় সংখ্যা পরীক্ষা করা সম্পূর্ণ বন্ধ করতে পারি। পরিবর্তে, আমাদের শুধুমাত্র বিজোড় সংখ্যা নিয়ে কাজ করতে হবে।
প্রথমত, এটি প্রয়োজনীয় মেমোরি অর্ধেক করতে দেবে। দ্বিতীয়ত, এটি অ্যালগরিদম দ্বারা সম্পাদিত অপারেশনের সংখ্যা প্রায় অর্ধেকে নামিয়ে আনবে।
মেমোরি ব্যবহার এবং অপারেশনের গতি#
লক্ষ্য করুন: এরাটোস্থেনিসের সিভের এই দুটি ইমপ্লিমেন্টেশন vector<bool> ডেটা স্ট্রাকচার ব্যবহার করে $n$ বিট মেমোরি ব্যবহার করে।
vector<bool> একটি সাধারণ কন্টেইনার নয় যা bool-এর একটি সিরিজ সংরক্ষণ করে (কারণ বেশিরভাগ কম্পিউটার আর্কিটেকচারে একটি bool এক বাইট মেমোরি নেয়)।
এটি vector<T>-এর একটি মেমোরি-অপটিমাইজেশন স্পেশালাইজেশন, যা মাত্র $\frac{N}{8}$ বাইট মেমোরি ব্যবহার করে।
আধুনিক প্রসেসর আর্কিটেকচার বিটের তুলনায় বাইটের সাথে অনেক বেশি দক্ষতার সাথে কাজ করে কারণ সেগুলো সাধারণত সরাসরি বিট অ্যাক্সেস করতে পারে না।
তাই vector<bool> অভ্যন্তরীণভাবে বিটগুলো একটি বড় ধারাবাহিক মেমোরিতে সংরক্ষণ করে, কয়েক বাইটের ব্লকে মেমোরি অ্যাক্সেস করে, এবং বিট মাস্কিং ও বিট শিফটিংয়ের মতো বিট অপারেশন দিয়ে বিট এক্সট্র্যাক্ট/সেট করে।
এই কারণে vector<bool>-এ বিট পড়া বা লেখার সময় কিছুটা ওভারহেড থাকে, এবং প্রায়ই vector<char> (যা প্রতিটি এন্ট্রির জন্য ১ বাইট ব্যবহার করে, অর্থাৎ ৮ গুণ বেশি মেমোরি) ব্যবহার করা দ্রুততর হয়।
তবে, এরাটোস্থেনিসের সিভের সরল ইমপ্লিমেন্টেশনের জন্য vector<bool> ব্যবহার করাই দ্রুততর।
আপনি ক্যাশে কত দ্রুত ডেটা লোড করতে পারবেন তার দ্বারা আপনি সীমাবদ্ধ, এবং তাই কম মেমোরি ব্যবহার একটি বড় সুবিধা দেয়।
একটি বেঞ্চমার্ক (link) দেখায় যে, vector<bool> ব্যবহার vector<char>-এর তুলনায় ১.৪ থেকে ১.৭ গুণ দ্রুততর।
একই বিবেচনা bitset-এর ক্ষেত্রেও প্রযোজ্য।
এটিও বিট সংরক্ষণের একটি দক্ষ উপায়, vector<bool>-এর মতো, তাই এটিও মাত্র $\frac{N}{8}$ বাইট মেমোরি নেয়, তবে উপাদান অ্যাক্সেসে কিছুটা ধীর।
উপরের বেঞ্চমার্কে bitset vector<bool>-এর তুলনায় কিছুটা খারাপ পারফর্ম করে।
bitset-এর আরেকটি অসুবিধা হলো কম্পাইল টাইমে সাইজ জানতে হয়।
সেগমেন্টেড সিভ#
“বর্গমূল পর্যন্ত সিভিং” অপটিমাইজেশন থেকে এটা স্পষ্ট যে পুরো অ্যারে is_prime[1...n] সবসময় রাখার প্রয়োজন নেই।
সিভিংয়ের জন্য শুধুমাত্র $n$-এর বর্গমূল পর্যন্ত মৌলিক সংখ্যাগুলো রাখাই যথেষ্ট, অর্থাৎ prime[1... sqrt(n)], সম্পূর্ণ পরিসরকে ব্লকে বিভক্ত করা, এবং প্রতিটি ব্লক আলাদাভাবে ছাঁকনি করা।
ধরা যাক $s$ একটি ধ্রুবক যা ব্লকের আকার নির্ধারণ করে, তাহলে মোট $\lceil {\frac n s} \rceil$ টি ব্লক থাকবে, এবং $k$-তম ব্লক ($k = 0 ... \lfloor {\frac n s} \rfloor$) $[ks; ks + s - 1]$ সেগমেন্টের সংখ্যাগুলো ধারণ করে। আমরা পালাক্রমে ব্লকগুলোতে কাজ করতে পারি, অর্থাৎ প্রতিটি ব্লক $k$-এর জন্য আমরা সকল মৌলিক সংখ্যার ($1$ থেকে $\sqrt n$ পর্যন্ত) মধ্য দিয়ে যাব এবং সেগুলো ব্যবহার করে সিভিং করব। লক্ষ্য করুন: প্রথম সংখ্যাগুলো হ্যান্ডেল করার সময় আমাদের কৌশলটি কিছুটা পরিবর্তন করতে হবে: প্রথমত, $[1; \sqrt n]$ থেকে সকল মৌলিক সংখ্যা নিজেদের মুছে ফেলবে না; এবং দ্বিতীয়ত, ০ এবং ১-কে অ-মৌলিক সংখ্যা হিসেবে চিহ্নিত করতে হবে। শেষ ব্লকে কাজ করার সময় ভুলে গেলে চলবে না যে শেষ প্রয়োজনীয় সংখ্যা $n$ অগত্যা ব্লকের শেষে অবস্থিত নাও হতে পারে।
পূর্বে যেমন আলোচনা করা হয়েছে, এরাটোস্থেনিসের সিভের সাধারণ ইমপ্লিমেন্টেশন CPU ক্যাশে কত দ্রুত ডেটা লোড করা যায় তার দ্বারা সীমাবদ্ধ।
সম্ভাব্য মৌলিক সংখ্যার পরিসর $[1; n]$-কে ছোট ব্লকে বিভক্ত করলে, আমাদের কখনোই একসাথে একাধিক ব্লক মেমোরিতে রাখতে হয় না, এবং সকল অপারেশন অনেক বেশি ক্যাশ-ফ্রেন্ডলি হয়।
যেহেতু আমরা এখন আর ক্যাশের গতি দ্বারা সীমাবদ্ধ নই, তাই আমরা vector<bool>-কে vector<char> দিয়ে প্রতিস্থাপন করতে পারি এবং কিছু অতিরিক্ত পারফরম্যান্স পেতে পারি কারণ প্রসেসরগুলো বাইটের সাথে সরাসরি রিড ও রাইট করতে পারে এবং পৃথক বিট এক্সট্র্যাক্ট করতে বিট অপারেশনের উপর নির্ভর করতে হয় না।
বেঞ্চমার্ক (link) দেখায় যে, এই পরিস্থিতিতে vector<char> ব্যবহার vector<bool>-এর তুলনায় প্রায় ৩ গুণ দ্রুততর।
সতর্কতার একটি কথা: এই সংখ্যাগুলো আর্কিটেকচার, কম্পাইলার এবং অপটিমাইজেশন লেভেলের উপর নির্ভর করে ভিন্ন হতে পারে।
এখানে আমাদের একটি ইমপ্লিমেন্টেশন আছে যা ব্লক সিভিং ব্যবহার করে $n$-এর চেয়ে ছোট বা সমান মৌলিক সংখ্যার সংখ্যা গণনা করে।
int count_primes(int n) {
const int S = 10000;
vector<int> primes;
int nsqrt = sqrt(n);
vector<char> is_prime(nsqrt + 2, true);
for (int i = 2; i <= nsqrt; i++) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * i; j <= nsqrt; j += i)
is_prime[j] = false;
}
}
int result = 0;
vector<char> block(S);
for (int k = 0; k * S <= n; k++) {
fill(block.begin(), block.end(), true);
int start = k * S;
for (int p : primes) {
int start_idx = (start + p - 1) / p;
int j = max(start_idx, p) * p - start;
for (; j < S; j += p)
block[j] = false;
}
if (k == 0)
block[0] = block[1] = false;
for (int i = 0; i < S && start + i <= n; i++) {
if (block[i])
result++;
}
}
return result;
}ব্লক সিভিংয়ের রানিং টাইম সাধারণ এরাটোস্থেনিসের সিভের মতোই (যদি না ব্লকের আকার খুব ছোট হয়), তবে প্রয়োজনীয় মেমোরি $O(\sqrt{n} + S)$-এ নেমে আসবে এবং আমরা আরও ভালো ক্যাশিং ফলাফল পাব। অন্যদিকে, $[1; \sqrt{n}]$ থেকে প্রতিটি ব্লক ও মৌলিক সংখ্যার জোড়ার জন্য একটি ভাগ অপারেশন থাকবে, এবং ছোট ব্লক সাইজের জন্য সেটি অনেক বেশি খারাপ হবে। সুতরাং, ধ্রুবক $S$ নির্বাচনে ভারসাম্য বজায় রাখা প্রয়োজন। আমরা $10^4$ থেকে $10^5$-এর মধ্যে ব্লক সাইজে সবচেয়ে ভালো ফলাফল পেয়েছি।
পরিসরে মৌলিক সংখ্যা খুঁজে বের করা#
কখনো কখনো আমাদের একটি ছোট আকারের পরিসর $[L,R]$-এ (যেমন $R - L + 1 \approx 1e7$) সকল মৌলিক সংখ্যা খুঁজে বের করতে হয়, যেখানে $R$ অনেক বড় হতে পারে (যেমন $1e12$)।
এই সমস্যা সমাধানে আমরা সেগমেন্টেড সিভের ধারণা ব্যবহার করতে পারি। আমরা $\sqrt R$ পর্যন্ত সকল মৌলিক সংখ্যা আগে থেকে জেনারেট করি এবং সেই মৌলিক সংখ্যাগুলো ব্যবহার করে $[L, R]$ সেগমেন্টে সকল যৌগিক সংখ্যা চিহ্নিত করি।
vector<char> segmentedSieve(long long L, long long R) {
// generate all primes up to sqrt(R)
long long lim = sqrt(R);
vector<char> mark(lim + 1, false);
vector<long long> primes;
for (long long i = 2; i <= lim; ++i) {
if (!mark[i]) {
primes.emplace_back(i);
for (long long j = i * i; j <= lim; j += i)
mark[j] = true;
}
}
vector<char> isPrime(R - L + 1, true);
for (long long i : primes)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}এই পদ্ধতির টাইম কমপ্লেক্সিটি হলো $O((R - L + 1) \log \log (R) + \sqrt R \log \log \sqrt R)$।
সকল মৌলিক সংখ্যা আগে থেকে জেনারেট না করেও এটি করা সম্ভব:
vector<char> segmentedSieveNoPreGen(long long L, long long R) {
vector<char> isPrime(R - L + 1, true);
long long lim = sqrt(R);
for (long long i = 2; i <= lim; ++i)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}স্পষ্টতই, কমপ্লেক্সিটি আরও খারাপ, যা $O((R - L + 1) \log (R) + \sqrt R)$। তবে, এটি বাস্তবে এখনও খুব দ্রুত চলে।
লিনিয়ার টাইম মডিফিকেশন#
আমরা অ্যালগরিদমটিকে এমনভাবে পরিবর্তন করতে পারি যাতে এর টাইম কমপ্লেক্সিটি শুধুমাত্র লিনিয়ার হয়। এই পদ্ধতিটি লিনিয়ার সিভ নিবন্ধে বর্ণিত হয়েছে। তবে, এই অ্যালগরিদমেরও নিজস্ব দুর্বলতা রয়েছে।
প্র্যাকটিস প্রবলেম#
- Leetcode - Four Divisors
- Leetcode - Count Primes
- SPOJ - Printing Some Primes
- SPOJ - A Conjecture of Paul Erdos
- SPOJ - Primal Fear
- SPOJ - Primes Triangle (I)
- Codeforces - Almost Prime
- Codeforces - Sherlock And His Girlfriend
- SPOJ - Namit in Trouble
- SPOJ - Bazinga!
- Project Euler - Prime pair connection
- SPOJ - N-Factorful
- SPOJ - Binary Sequence of Prime Numbers
- UVA 11353 - A Different Kind of Sorting
- SPOJ - Prime Generator
- SPOJ - Printing some primes (hard)
- Codeforces - Nodbach Problem
- Codeforces - Colliders