ডিসজয়েন্ট সেট ইউনিয়ন#
এই আর্টিকেলে ডিসজয়েন্ট সেট ইউনিয়ন বা ডিএসইউ ডাটা স্ট্রাকচার নিয়ে আলোচনা করব। এটাকে অনেক সময় ইউনিয়ন-ফাইন্ড-ও বলে, কারণ এর দুটো প্রধান অপারেশন আছে।
ব্যাপারটা এরকম — তোমাকে কয়েকটা এলিমেন্ট দেওয়া আছে, প্রতিটা আলাদা একটা সেটে আছে। ডিএসইউ দিয়ে তুমি যেকোনো দুটো সেট মার্জ করতে পারবে, আর বলতে পারবে কোনো নির্দিষ্ট এলিমেন্ট কোন সেটে আছে। ক্লাসিক্যাল ভার্সনে আরেকটা অপারেশনও আছে — নতুন একটা এলিমেন্ট দিয়ে সেট বানানো।
তাহলে এই ডাটা স্ট্রাকচারের বেসিক ইন্টারফেসে মোট তিনটা অপারেশন:
make_set(v)- নতুন এলিমেন্টvদিয়ে একটা নতুন সেট বানায়union_sets(a, b)- দুটো সেটকে মার্জ করে (যে সেটেaআছে আর যে সেটেbআছে)find_set(v)- এলিমেন্টvযে সেটে আছে, সেই সেটের রিপ্রেজেন্টেটিভ (লিডার) রিটার্ন করে। এই রিপ্রেজেন্টেটিভ হলো সেই সেটেরই একটা এলিমেন্ট। ডাটা স্ট্রাকচার নিজেই এটা সিলেক্ট করে (আর সময়ের সাথে বদলাতেও পারে, বিশেষতunion_setsকলের পরে)। এই রিপ্রেজেন্টেটিভ দিয়ে তুমি চেক করতে পারবে দুটো এলিমেন্ট একই সেটে আছে কি না।aআরbএকই সেটে থাকবে যদি এবং কেবল যদিfind_set(a) == find_set(b)হয়। না হলে তারা আলাদা সেটে আছে।
পরে আমরা দেখব যে এই ডাটা স্ট্রাকচার গড়ে প্রায় $O(1)$ সময়ে প্রতিটা অপারেশন করতে পারে।
এছাড়াও একটা সাবসেকশনে ডিএসইউ-এর একটা বিকল্প স্ট্রাকচার দেখানো হয়েছে, যেটা $O(\log n)$ গড় কমপ্লেক্সিটি দেয়, কিন্তু সাধারণ ডিএসইউ-এর চেয়ে আরও পাওয়ারফুল হতে পারে।
একটা এফিশিয়েন্ট ডাটা স্ট্রাকচার বানানো#
আমরা সেটগুলো ট্রি আকারে রাখব — প্রতিটা ট্রি একটা সেটের সাথে ম্যাপ হবে। আর ট্রির রুট হবে সেই সেটের রিপ্রেজেন্টেটিভ/লিডার।
নিচের ছবিতে তুমি এই ধরনের ট্রির রিপ্রেজেন্টেশন দেখতে পারবে।
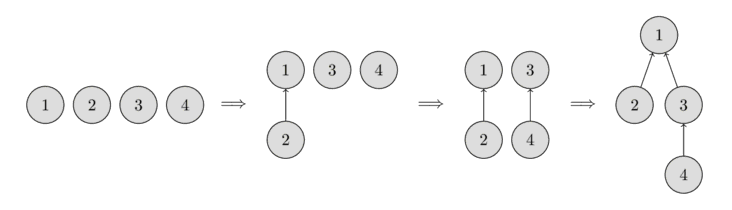
শুরুতে প্রতিটা এলিমেন্ট আলাদা একটা সেটে থাকে, তাই প্রতিটা ভার্টেক্স নিজেই একটা ট্রি। তারপর আমরা 1 এর সেট আর 2 এর সেট মার্জ করি। তারপর 3 এর সেট আর 4 এর সেট মার্জ করি। আর শেষ ধাপে, 1 এর সেট আর 3 এর সেট মার্জ করি।
ইমপ্লিমেন্টেশনের জন্য আমাদের একটা parent অ্যারে রাখতে হবে, যেটা প্রতিটা নোডের ট্রিতে সরাসরি প্যারেন্টের রেফারেন্স রাখবে।
নেইভ ইমপ্লিমেন্টেশন#
চলো এখন DSU-এর প্রথম ইমপ্লিমেন্টেশনটা লিখি। প্রথমে এটা বেশ স্লো হবে, কিন্তু পরে দুটো অপটিমাইজেশন দিয়ে এটাকে এত ফাস্ট করব যে প্রতিটা ফাংশন কলে প্রায় কনস্ট্যান্ট সময় লাগবে।
আগেই বলেছি, সব তথ্য একটা parent অ্যারেতে রাখব।
নতুন সেট বানাতে (অপারেশন make_set(v)), আমরা শুধু v-কে রুট হিসেবে নিয়ে একটা ট্রি বানাই — মানে v নিজেই নিজের প্যারেন্ট।
দুটো সেট মার্জ করতে (অপারেশন union_sets(a, b)), আমরা প্রথমে a এর সেটের রিপ্রেজেন্টেটিভ বের করি, তারপর b এর সেটের রিপ্রেজেন্টেটিভ বের করি।
যদি দুটো রিপ্রেজেন্টেটিভ একই হয়, তাহলে কিছু করার নেই — সেটগুলো আগে থেকেই মার্জ করা।
না হলে, একটা রিপ্রেজেন্টেটিভকে অন্যটার প্যারেন্ট বানিয়ে দিই — এভাবে দুটো ট্রি জোড়া লেগে যায়।
সবশেষে রিপ্রেজেন্টেটিভ খোঁজার ফাংশন (অপারেশন find_set(v)):
আমরা v থেকে শুরু করে প্যারেন্ট ধরে ধরে উপরে উঠি যতক্ষণ না রুটে পৌঁছাই — মানে যে নোডের প্যারেন্ট সে নিজেই।
এটা রিকার্সিভভাবে খুব সহজেই লেখা যায়।
void make_set(int v) {
parent[v] = v;
}
int find_set(int v) {
if (v == parent[v])
return v;
return find_set(parent[v]);
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b)
parent[b] = a;
}কিন্তু এই ইমপ্লিমেন্টেশন বেশ স্লো।
সহজেই এমন কেস বানানো যায় যেখানে ট্রিগুলো লম্বা চেইনে পরিণত হয়।
তখন প্রতিটা find_set(v) কলে $O(n)$ সময় লাগতে পারে।
এটা আমরা যেটা চাই (প্রায় কনস্ট্যান্ট সময়) তার থেকে অনেক দূরে। তাই চলো দুটো অপটিমাইজেশন দেখি যেগুলো এটাকে অনেক ফাস্ট করে দেবে।
পাথ কম্প্রেশন অপটিমাইজেশন#
এই অপটিমাইজেশনটা find_set-কে ফাস্ট করার জন্য।
ধরো তুমি কোনো ভার্টেক্স v-এর জন্য find_set(v) কল করলে। v থেকে রুট p পর্যন্ত যেতে যেতে তুমি পথের সব ভার্টেক্স ভিজিট করবে।
ট্রিকটা হলো — এই সব নোডের প্যারেন্ট সরাসরি p-তে সেট করে দাও। এতে পাথ অনেক ছোট হয়ে যায়।
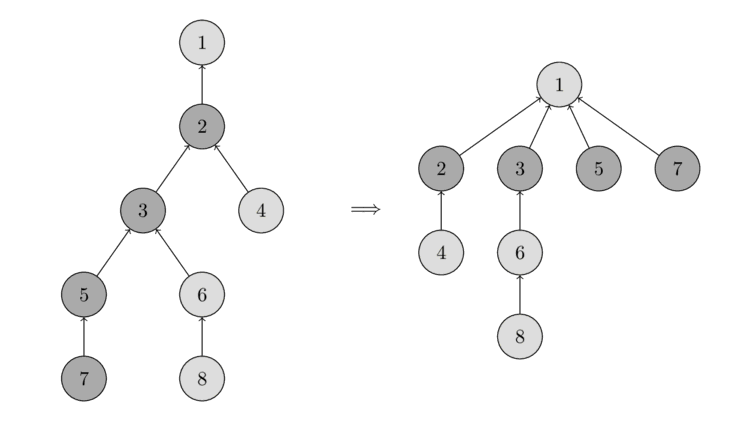
নিচের ছবিতে দেখো।
বাঁদিকে একটা ট্রি আছে, আর ডানদিকে find_set(7) কল করার পরে কম্প্রেসড ট্রি — ভিজিটেড নোড 7, 5, 3 আর 2-এর পাথ ছোট হয়ে গেছে।
find_set-এর নতুন ইমপ্লিমেন্টেশন এরকম:
int find_set(int v) {
if (v == parent[v])
return v;
return parent[v] = find_set(parent[v]);
}এই সিম্পল ইমপ্লিমেন্টেশন ঠিক সেটাই করে যেটা আমরা চেয়েছিলাম: প্রথমে সেটের রিপ্রেজেন্টেটিভ (রুট ভার্টেক্স) বের করে, তারপর রিকার্সন ফিরে আসার সময় পথের সব নোডকে সরাসরি রুটের সাথে জুড়ে দেয়।
এই ছোট্ট পরিবর্তনটাই গড়ে প্রতি কলে $O(\log n)$ কমপ্লেক্সিটি এনে দেয় (প্রুফ এখানে দেখাচ্ছি না)। আরেকটা অপটিমাইজেশন আছে যেটা এটাকে আরও ফাস্ট করবে।
ইউনিয়ন বাই সাইজ / র্যাঙ্ক#
এই অপটিমাইজেশনে আমরা union_set অপারেশনটা বদলাব।
সোজা কথায়, আমরা ঠিক করব কোন ট্রি কোনটার সাথে জুড়বে।
নেইভ ইমপ্লিমেন্টেশনে দ্বিতীয় ট্রি সবসময় প্রথমটার সাথে জুড়ত।
এতে $O(n)$ লম্বা চেইন তৈরি হতে পারে।
এই অপটিমাইজেশনে আমরা বুদ্ধি করে বেছে নেব কোন ট্রি কোনটার নিচে যাবে।
অনেক হিউরিস্টিক ব্যবহার করা যায়। সবচেয়ে জনপ্রিয় দুটো হলো: প্রথমটায় আমরা ট্রির সাইজকে র্যাঙ্ক হিসেবে ধরি, আর দ্বিতীয়টায় ট্রির ডেপথ ধরি (আরও সঠিকভাবে বলতে গেলে, ডেপথের আপার বাউন্ড — কারণ পাথ কম্প্রেশন করলে ডেপথ কমে যায়)।
দুটো পদ্ধতির মূল আইডিয়া একই: ছোট র্যাঙ্কের ট্রিকে বড় র্যাঙ্কের ট্রির সাথে জুড়ে দাও।
ইউনিয়ন বাই সাইজের ইমপ্লিমেন্টেশন:
void make_set(int v) {
parent[v] = v;
size[v] = 1;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (size[a] < size[b])
swap(a, b);
parent[b] = a;
size[a] += size[b];
}
}আর এখানে ট্রির ডেপথ ভিত্তিক ইউনিয়ন বাই র্যাঙ্কের ইমপ্লিমেন্টেশন:
void make_set(int v) {
parent[v] = v;
rank[v] = 0;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = a;
if (rank[a] == rank[b])
rank[a]++;
}
}দুটো অপটিমাইজেশন টাইম আর স্পেস কমপ্লেক্সিটির দিক থেকে একই। তাই বাস্তবে তুমি যেকোনোটা ব্যবহার করতে পারবে।
টাইম কমপ্লেক্সিটি#
আগেই বলেছি, দুটো অপটিমাইজেশন একসাথে ব্যবহার করলে — পাথ কম্প্রেশন + ইউনিয়ন বাই সাইজ / র্যাঙ্ক — প্রায় কনস্ট্যান্ট সময়ের কুয়েরি পাওয়া যায়। অ্যামোরটাইজড টাইম কমপ্লেক্সিটি দাঁড়ায় $O(\alpha(n))$, যেখানে $\alpha(n)$ হলো ইনভার্স অ্যাকারম্যান ফাংশন — এটা এত ধীরে বাড়ে যে ব্যবহারিক সব $n$-এর জন্য (মোটামুটি $n < 10^{600}$) এটা $4$-এর বেশি হয় না।
অ্যামোরটাইজড কমপ্লেক্সিটি মানে হলো অনেকগুলো অপারেশনের সিকোয়েন্সের উপর প্রতি অপারেশনে গড় সময়। আইডিয়াটা হলো পুরো সিকোয়েন্সের মোট সময়ের গ্যারান্টি দেওয়া, যদিও একটা সিঙ্গেল অপারেশন অ্যামোরটাইজড সময়ের চেয়ে অনেক স্লো হতে পারে। যেমন, আমাদের কেসে একটা সিঙ্গেল কলে ওয়ার্স্ট কেসে $O(\log n)$ লাগতে পারে, কিন্তু পরপর $m$ টা কল করলে গড় সময় $O(\alpha(n))$ হবে।
এই কমপ্লেক্সিটির প্রুফ এখানে দেখাচ্ছি না, কারণ সেটা বেশ লম্বা আর জটিল।
আরেকটা কথা — ইউনিয়ন বাই সাইজ / র্যাঙ্ক ব্যবহার করলে কিন্তু পাথ কম্প্রেশন না করলে, DSU প্রতি কুয়েরিতে $O(\log n)$ সময়ে কাজ করে।
ইনডেক্স দ্বারা লিংকিং / কয়েন-ফ্লিপ লিংকিং#
ইউনিয়ন বাই র্যাঙ্ক আর ইউনিয়ন বাই সাইজ — দুটোতেই প্রতিটা সেটে এক্সট্রা ডাটা রাখতে হয় আর প্রতি ইউনিয়নে সেগুলো মেইনটেইন করতে হয়। একটা র্যান্ডমাইজড অ্যালগরিদমও আছে যেটা ইউনিয়ন অপারেশনকে সিম্পল করে: ইনডেক্স দ্বারা লিংকিং।
আমরা প্রতিটা সেটকে একটা র্যান্ডম ভ্যালু দিই — এটাকে ইনডেক্স বলি — আর ছোট ইনডেক্সের সেটটাকে বড় ইনডেক্সের সেটের সাথে জুড়ে দিই। বড় সেটের ইনডেক্স সাধারণত ছোট সেটের চেয়ে বড় হবে, তাই এটা ইউনিয়ন বাই সাইজের সাথে খুব কাছাকাছি। আসলে প্রুফ করা যায় যে এর কমপ্লেক্সিটি ইউনিয়ন বাই সাইজের সমান। তবে প্র্যাকটিসে এটা ইউনিয়ন বাই সাইজের চেয়ে একটু স্লো।
কমপ্লেক্সিটির প্রুফ আর আরও ইউনিয়ন টেকনিক এখানে পাবে।
void make_set(int v) {
parent[v] = v;
index[v] = rand();
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (index[a] < index[b])
swap(a, b);
parent[b] = a;
}
}একটা কমন ভুল ধারণা হলো — শুধু কয়েন ফ্লিপ করে (মানে র্যান্ডমলি) ঠিক করলে কোন সেট কোনটার সাথে জুড়বে, তাহলেও একই কমপ্লেক্সিটি পাওয়া যাবে। কিন্তু এটা সত্য না। উপরে লিংক করা পেপারে দেখানো হয়েছে যে কয়েন-ফ্লিপ লিংকিং পাথ কম্প্রেশনের সাথে মিলিয়ে $\Omega\left(n \frac{\log n}{\log \log n}\right)$ কমপ্লেক্সিটি দেয়। আর বেঞ্চমার্কেও এটা ইউনিয়ন বাই সাইজ/র্যাঙ্ক বা ইনডেক্স দ্বারা লিংকিংয়ের তুলনায় অনেক খারাপ পারফর্ম করে।
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rand() % 2)
swap(a, b);
parent[b] = a;
}
}অ্যাপ্লিকেশন এবং বিভিন্ন উন্নতি#
এই সেকশনে আমরা ডাটা স্ট্রাকচারটার বেশ কিছু অ্যাপ্লিকেশন দেখব — সাধারণ ব্যবহার আর কিছু ইমপ্রুভমেন্ট দুটোই।
গ্রাফে কানেক্টেড কম্পোনেন্ট#
এটা DSU-এর সবচেয়ে সোজাসুজি অ্যাপ্লিকেশনগুলোর একটা।
সমস্যাটা এরকম: শুরুতে একটা খালি গ্রাফ আছে। তোমাকে ভার্টেক্স আর আনডিরেক্টেড এজ যোগ করতে হবে, আর $(a, b)$ টাইপের কুয়েরির উত্তর দিতে হবে — “ভার্টেক্স $a$ আর $b$ কি একই কানেক্টেড কম্পোনেন্টে আছে?”
এখানে আমরা সরাসরি DSU অ্যাপ্লাই করতে পারি, আর গড়ে প্রায় কনস্ট্যান্ট সময়ে ভার্টেক্স/এজ যোগ আর কুয়েরি হ্যান্ডেল করতে পারি।
এই অ্যাপ্লিকেশনটা বেশ গুরুত্বপূর্ণ, কারণ প্রায় একই সমস্যা ক্রুস্কালের মিনিমাম স্প্যানিং ট্রি অ্যালগরিদমে দেখা যায়। DSU ব্যবহার করে আমরা $O(m \log n + n^2)$ কমপ্লেক্সিটিকে $O(m \log n)$-এ নামিয়ে আনতে পারি।
একটি ইমেজে কানেক্টেড কম্পোনেন্ট খোঁজা#
DSU-এর একটা অ্যাপ্লিকেশন হলো এরকম: $n \times m$ পিক্সেলের একটা ইমেজ আছে। শুরুতে সব সাদা, তারপর কিছু কালো পিক্সেল আঁকা হয়। তোমাকে ফাইনাল ইমেজে প্রতিটা সাদা কানেক্টেড কম্পোনেন্টের সাইজ বের করতে হবে।
সমাধান সিম্পল — ইমেজের সব সাদা পিক্সেলের উপর ইটারেট করো, প্রতিটা সেলের 4 টা নেইবার চেক করো, নেইবার সাদা হলে union_sets কল করো।
এভাবে $n \cdot m$ টা নোডের একটা DSU পেয়ে যাবে।
DSU-এর ট্রিগুলোই হবে তোমার কানেক্টেড কম্পোনেন্ট।
সমস্যাটা DFS বা BFS দিয়েও সলভ করা যায়, কিন্তু এই পদ্ধতির একটা সুবিধা আছে: এটা ম্যাট্রিক্স রো বাই রো প্রসেস করতে পারে (মানে একটা রো প্রসেস করতে শুধু আগের আর বর্তমান রো দরকার) — মাত্র $O(\min(n, m))$ মেমোরিতে।
প্রতিটি সেটে অতিরিক্ত তথ্য সংরক্ষণ#
DSU দিয়ে তুমি সহজেই সেটগুলোতে এক্সট্রা তথ্য রাখতে পারবে।
সিম্পল উদাহরণ হলো সেটের সাইজ: ইউনিয়ন বাই সাইজ সেকশনে এটা আগেই দেখিয়েছি (ইনফরমেশনটা সেটের রিপ্রেজেন্টেটিভ নোডে রাখা হতো)।
একইভাবে — রিপ্রেজেন্টেটিভ নোডে রেখে — তুমি সেটগুলো সম্পর্কে যেকোনো তথ্য রাখতে পারবে।
সেগমেন্ট বরাবর জাম্প কম্প্রেস করা / অফলাইনে সাবঅ্যারে পেইন্টিং#
DSU-এর একটা কমন অ্যাপ্লিকেশন এরকম: কিছু ভার্টেক্স দেওয়া আছে, প্রতিটার অন্য একটা ভার্টেক্সে আউটগোয়িং এজ আছে। DSU দিয়ে তুমি প্রায় কনস্ট্যান্ট সময়ে যেকোনো স্টার্টিং পয়েন্ট থেকে সব এজ ফলো করে শেষ পয়েন্টটা বের করতে পারবে।
এর একটা ভালো উদাহরণ হলো সাবঅ্যারে পেইন্টিং প্রবলেম। $L$ দৈর্ঘ্যের একটা সেগমেন্ট আছে, শুরুতে সব এলিমেন্টের রং 0। প্রতিটা কুয়েরি $(l, r, c)$-এর জন্য তোমাকে সাবঅ্যারে $[l, r]$-কে রং $c$ দিয়ে পেইন্ট করতে হবে। শেষে প্রতিটা সেলের ফাইনাল রং বের করতে হবে। আমরা ধরে নিচ্ছি সব কুয়েরি আগে থেকে জানা — মানে কাজটা অফলাইন।
সমাধানের জন্য একটা DSU বানাব যেটা প্রতিটা সেলের জন্য পরবর্তী আনপেইন্টেড সেলের লিংক রাখবে। শুরুতে প্রতিটা সেল নিজেকেই পয়েন্ট করে। একটা সেগমেন্ট পেইন্ট করার পর, সেই সেগমেন্টের সব সেল সেগমেন্টের পরের সেলকে পয়েন্ট করবে।
এখন সমস্যা সলভ করতে আমরা কুয়েরিগুলো উল্টো ক্রমে প্রসেস করি — শেষ থেকে প্রথমে। এভাবে যখন একটা কুয়েরি এক্সিকিউট করি, শুধু $[l, r]$-এ আনপেইন্টেড সেলগুলোই পেইন্ট করতে হয়। বাকি সেলে আগেই ফাইনাল রং বসে গেছে। আনপেইন্টেড সেলগুলোতে দ্রুত ইটারেট করতে আমরা DSU ব্যবহার করি। সেগমেন্টের মধ্যে সবচেয়ে বামের আনপেইন্টেড সেল খুঁজি, পেইন্ট করি, তারপর পয়েন্টার দিয়ে ডানে পরবর্তী খালি সেলে চলে যাই।
এখানে পাথ কম্প্রেশনসহ DSU ব্যবহার করতে পারি, কিন্তু ইউনিয়ন বাই র্যাঙ্ক / সাইজ পারি না (কারণ মার্জের পর কে লিডার হবে সেটা গুরুত্বপূর্ণ)। তাই কমপ্লেক্সিটি হবে প্রতি ইউনিয়নে $O(\log n)$ (যেটা বেশ ফাস্টও)।
ইমপ্লিমেন্টেশন:
for (int i = 0; i <= L; i++) {
make_set(i);
}
for (int i = m-1; i >= 0; i--) {
int l = query[i].l;
int r = query[i].r;
int c = query[i].c;
for (int v = find_set(l); v <= r; v = find_set(v)) {
answer[v] = c;
parent[v] = v + 1;
}
}একটা অপটিমাইজেশন আছে:
পরবর্তী আনপেইন্টেড সেল আলাদা একটা অ্যারে end[]-এ রাখলে আমরা ইউনিয়ন বাই র্যাঙ্ক / সাইজও ব্যবহার করতে পারি।
তাহলে হিউরিস্টিক অনুযায়ী দুটো সেট মার্জ করতে পারি, আর $O(\alpha(n))$-এ সমাধান পাই।
রিপ্রেজেন্টেটিভ পর্যন্ত দূরত্ব সাপোর্ট#
অনেক সময় DSU-এর কিছু অ্যাপ্লিকেশনে একটা ভার্টেক্স থেকে তার সেটের রিপ্রেজেন্টেটিভ পর্যন্ত দূরত্ব (মানে ট্রিতে বর্তমান নোড থেকে রুট পর্যন্ত পাথের দৈর্ঘ্য) মেইনটেইন করতে হয়।
পাথ কম্প্রেশন ছাড়া করলে দূরত্ব হলো রিকার্সিভ কলের সংখ্যা। কিন্তু সেটা স্লো হবে।
তবে পাথ কম্প্রেশনও করা যায় — প্রতিটা নোডের জন্য এক্সট্রা ইনফো হিসেবে প্যারেন্ট পর্যন্ত দূরত্ব রাখলেই হয়।
ইমপ্লিমেন্টেশনে parent[]-এর জন্য পেয়ারের অ্যারে ব্যবহার করা সুবিধাজনক। find_set ফাংশন এখন দুটো জিনিস রিটার্ন করবে: সেটের রিপ্রেজেন্টেটিভ আর দূরত্ব।
void make_set(int v) {
parent[v] = make_pair(v, 0);
rank[v] = 0;
}
pair<int, int> find_set(int v) {
if (v != parent[v].first) {
int len = parent[v].second;
parent[v] = find_set(parent[v].first);
parent[v].second += len;
}
return parent[v];
}
void union_sets(int a, int b) {
a = find_set(a).first;
b = find_set(b).first;
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = make_pair(a, 1);
if (rank[a] == rank[b])
rank[a]++;
}
}পাথ দৈর্ঘ্যের প্যারিটি সাপোর্ট / অনলাইনে বাইপার্টাইটনেস চেক করা#
লিডার পর্যন্ত পাথের দৈর্ঘ্য গণনার মতোই, পাথের দৈর্ঘ্যের প্যারিটিও মেইনটেইন করা সম্ভব। কেন এটা আলাদা সেকশনে? কারণ এর একটা ইন্টারেস্টিং ইউজ কেস আছে।
পাথের প্যারিটি কাজে আসে এই প্রবলেমে: শুরুতে একটা খালি গ্রাফ দেওয়া আছে, এজ যোগ করা যায়, আর তোমাকে এই ধরনের কুয়েরির উত্তর দিতে হবে — “এই ভার্টেক্সের কানেক্টেড কম্পোনেন্টটা কি বাইপার্টাইট?”
সলভ করতে আমরা কম্পোনেন্ট রাখার জন্য একটা DSU বানাই আর প্রতিটা ভার্টেক্সের জন্য রিপ্রেজেন্টেটিভ পর্যন্ত পাথের প্যারিটি রাখি। এভাবে দ্রুত চেক করতে পারি একটা এজ যোগ করলে বাইপার্টাইটনেস নষ্ট হবে কি না: যদি এজের দুটো প্রান্ত একই কম্পোনেন্টে থাকে আর লিডার পর্যন্ত একই প্যারিটি দৈর্ঘ্য থাকে, তাহলে এই এজ যোগ করলে বিজোড় দৈর্ঘ্যের সাইকেল তৈরি হবে — আর কম্পোনেন্টটা বাইপার্টাইট থাকবে না।
একটু ট্রিকি পার্ট হলো union_find মেথডে প্যারিটি ক্যালকুলেট করা।
ধরো একটা এজ $(a, b)$ যোগ করছ যেটা দুটো কম্পোনেন্টকে জোড়া লাগাবে। একটা ট্রিকে অন্যটার সাথে জুড়তে গেলে প্যারিটি অ্যাডজাস্ট করতে হবে।
চলো ফর্মুলা বের করি। ধরি $x$ হলো $a$ থেকে তার লিডার $A$ পর্যন্ত পাথের প্যারিটি, $y$ হলো $b$ থেকে তার লিডার $B$ পর্যন্ত পাথের প্যারিটি, আর $t$ হলো মার্জের পর $B$-কে দেওয়া প্যারিটি। পাথটা তিন ভাগে ভাগ করা যায়: $B$ থেকে $b$, তারপর $b$ থেকে $a$ (একটা এজ, তাই প্যারিটি $1$), তারপর $a$ থেকে $A$। তাহলে ফর্মুলা দাঁড়ায় ($\oplus$ মানে XOR):
$$t = x \oplus y \oplus 1$$তারমানে যতগুলো জয়েনই হোক না কেন, এজের প্যারিটি ঠিকভাবে এক লিডার থেকে অন্য লিডারে চলে যায়।
এখানে প্যারিটি সাপোর্টসহ DSU-এর ইমপ্লিমেন্টেশন দিচ্ছি। আগের সেকশনের মতো প্যারেন্ট আর প্যারিটি রাখতে পেয়ার ব্যবহার করছি। আর প্রতিটা সেটের জন্য bipartite[] অ্যারেতে রাখছি সেটা এখনো বাইপার্টাইট কি না।
void make_set(int v) {
parent[v] = make_pair(v, 0);
rank[v] = 0;
bipartite[v] = true;
}
pair<int, int> find_set(int v) {
if (v != parent[v].first) {
int parity = parent[v].second;
parent[v] = find_set(parent[v].first);
parent[v].second ^= parity;
}
return parent[v];
}
void add_edge(int a, int b) {
pair<int, int> pa = find_set(a);
a = pa.first;
int x = pa.second;
pair<int, int> pb = find_set(b);
b = pb.first;
int y = pb.second;
if (a == b) {
if (x == y)
bipartite[a] = false;
} else {
if (rank[a] < rank[b])
swap (a, b);
parent[b] = make_pair(a, x^y^1);
bipartite[a] &= bipartite[b];
if (rank[a] == rank[b])
++rank[a];
}
}
bool is_bipartite(int v) {
return bipartite[find_set(v).first];
}গড়ে $O(\alpha(n))$-এ অফলাইন RMQ / আরপার ট্রিক#
একটা অ্যারে a[] দেওয়া আছে আর কিছু সেগমেন্টে মিনিমাম বের করতে হবে।
DSU দিয়ে সলভ করার আইডিয়াটা এরকম:
অ্যারের উপর ইটারেট করব, আর i-তম এলিমেন্টে থাকতে থাকতে R == i এমন সব কুয়েরি (L, R) এর উত্তর দেব।
এটা এফিশিয়েন্টলি করতে প্রথম i টা এলিমেন্ট নিয়ে একটা DSU বানাব এভাবে: প্রতিটা এলিমেন্টের প্যারেন্ট হলো তার ডানে পরবর্তী ছোট এলিমেন্ট।
তাহলে একটা কুয়েরির উত্তর হবে a[find_set(L)] — মানে L-এর ডানে সবচেয়ে ছোট সংখ্যা।
বুঝতেই পারছ এটা শুধু অফলাইনে কাজ করে — সব কুয়েরি আগে থেকে জানা থাকতে হবে।
এখানে পাথ কম্প্রেশন অ্যাপ্লাই করা যায়। ইউনিয়ন বাই র্যাঙ্কও ব্যবহার করা যায়, যদি প্রকৃত লিডার আলাদা একটা অ্যারেতে রাখ।
struct Query {
int L, R, idx;
};
vector<int> answer;
vector<vector<Query>> container;container[i]-তে R == i এমন সব কুয়েরি থাকে।
stack<int> s;
for (int i = 0; i < n; i++) {
while (!s.empty() && a[s.top()] > a[i]) {
parent[s.top()] = i;
s.pop();
}
s.push(i);
for (Query q : container[i]) {
answer[q.idx] = a[find_set(q.L)];
}
}এই অ্যালগরিদমটা আরপার ট্রিক নামে পরিচিত। AmirReza Poorakhavan-এর নামে নামকরণ করা হয়েছে, যিনি স্বতন্ত্রভাবে এই ট্রিকটা আবিষ্কার আর জনপ্রিয় করেছিলেন। তবে তাঁর আবিষ্কারের আগেই এই অ্যালগরিদম ছিল।
গড়ে $O(\alpha(n))$-এ অফলাইন LCA#
LCA বের করার অ্যালগরিদম LCA - টারজানের অফলাইন অ্যালগরিদম আর্টিকেলে দেওয়া আছে। এই অ্যালগরিদমটা অন্যান্য LCA অ্যালগরিদমের তুলনায় সিম্পল (বিশেষত ফারাক-কোলটন আর বেন্ডার-এর মতো অপটিমাল অ্যালগরিদমের চেয়ে)।
ডিএসইউকে সেট লিস্টে এক্সপ্লিসিটলি সংরক্ষণ / বিভিন্ন ডেটা স্ট্রাকচার মার্জ করার সময় এই ধারণার অ্যাপ্লিকেশন#
DSU রাখার আরেকটা উপায় হলো প্রতিটা সেটকে এলিমেন্টের এক্সপ্লিসিট লিস্ট হিসেবে রাখা। প্রতিটা এলিমেন্ট তার সেটের রিপ্রেজেন্টেটিভের রেফারেন্সও রাখে।
প্রথম দেখায় মনে হবে এটা ইনএফিশিয়েন্ট: দুটো সেট মার্জ করতে একটা লিস্ট অন্যটার শেষে জুড়তে হবে আর একটা লিস্টের সব এলিমেন্টে লিডার আপডেট করতে হবে।
কিন্তু ওয়েটিং হিউরিস্টিক (ইউনিয়ন বাই সাইজের মতো) ব্যবহার করলে কমপ্লেক্সিটি অনেক কমে যায়: $n$ টা এলিমেন্টে $m$ টা কুয়েরি করতে $O(m + n \log n)$।
ওয়েটিং হিউরিস্টিক মানে — সবসময় ছোট সেটটাকে বড় সেটে যোগ করব।
union_sets-এ এটা সহজেই করা যায়, আর সময় লাগবে যোগ করা সেটের সাইজের সমানুপাতিক।
আর find_set-এ লিডার বের করা এই পদ্ধতিতে $O(1)$।
চলো প্রুফ করি $m$ টা কুয়েরির টাইম কমপ্লেক্সিটি $O(m + n \log n)$। একটা নির্দিষ্ট এলিমেন্ট $x$ ধরো আর গুনো মার্জ অপারেশনে কতবার এটাকে সরানো হয়েছে। $x$-কে যখন প্রথমবার সরানো হয়, নতুন সেটের সাইজ কমপক্ষে $2$। দ্বিতীয়বার সরানো হলে, সেটের সাইজ কমপক্ষে $4$ — কারণ ছোট সেটটাই বড়টাতে যোগ হচ্ছে। এভাবে চলতে থাকে। তারমানে $x$-কে সর্বাধিক $\log n$ বার সরানো যায়। সব ভার্টেক্স মিলিয়ে $O(n \log n)$, আর প্রতিটা কুয়েরিতে $O(1)$।
ইমপ্লিমেন্টেশনটা এরকম:
vector<int> lst[MAXN];
int parent[MAXN];
void make_set(int v) {
lst[v] = vector<int>(1, v);
parent[v] = v;
}
int find_set(int v) {
return parent[v];
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (lst[a].size() < lst[b].size())
swap(a, b);
while (!lst[b].empty()) {
int v = lst[b].back();
lst[b].pop_back();
parent[v] = a;
lst[a].push_back (v);
}
}
}ছোট অংশকে বড় অংশে যোগ করার এই আইডিয়াটা DSU ছাড়াও অনেক জায়গায় কাজে আসে।
যেমন এই প্রবলেমটা দেখো: একটা ট্রি দেওয়া আছে, প্রতিটা লিফে একটা সংখ্যা আছে (একই সংখ্যা একাধিক লিফে থাকতে পারে)। তোমাকে ট্রির প্রতিটা নোডের জন্য বের করতে হবে তার সাবট্রিতে কতগুলো ডিস্টিংক্ট সংখ্যা আছে।
একই আইডিয়া দিয়ে সলভ করা যায়: একটা DFS লিখো যেটা পূর্ণসংখ্যার সেটের পয়েন্টার রিটার্ন করে — সেই সাবট্রিতে কোন কোন সংখ্যা আছে। বর্তমান নোডের উত্তর পেতে (যদি না সেটা লিফ হয়), সব চাইল্ডের জন্য DFS কল করো আর প্রাপ্ত সেটগুলো মার্জ করো। মার্জ হওয়া সেটের সাইজই হলো বর্তমান নোডের উত্তর। সেটগুলো এফিশিয়েন্টলি মার্জ করতে উপরের পদ্ধতিই অ্যাপ্লাই করো — ছোটটাকে বড়টাতে যোগ করো। এভাবে $O(n \log^2 n)$ সমাধান পাওয়া যায়, কারণ একটা সংখ্যা সর্বাধিক $O(\log n)$ বার সেটে যোগ হবে।
স্পষ্ট ট্রি স্ট্রাকচার বজায় রেখে ডিএসইউ সংরক্ষণ / গড়ে $O(\alpha(n))$-এ অনলাইন ব্রিজ খোঁজা#
DSU-এর সবচেয়ে পাওয়ারফুল অ্যাপ্লিকেশনগুলোর একটা হলো — তুমি কম্প্রেসড আর আনকম্প্রেসড দুটো ট্রিই রাখতে পারবে। কম্প্রেসড ফর্ম দিয়ে ট্রি মার্জ করবে আর চেক করবে দুটো ভার্টেক্স একই ট্রিতে আছে কি না। আর আনকম্প্রেসড ফর্ম দিয়ে — যেমন — দুটো ভার্টেক্সের মধ্যে পাথ বের করতে পারবে, বা ট্রি ট্রাভার্স করতে পারবে।
ইমপ্লিমেন্টেশনে কম্প্রেসড অ্যানসেস্টর অ্যারে parent[] ছাড়াও একটা আনকম্প্রেসড অ্যানসেস্টরের অ্যারে real_parent[] রাখতে হবে।
এই এক্সট্রা অ্যারে মেইনটেইন করলে কমপ্লেক্সিটি খারাপ হয় না — চেঞ্জ শুধু তখনই হয় যখন দুটো ট্রি মার্জ করি, আর তাও শুধু একটা এলিমেন্টে।
তবে প্র্যাকটিসে অনেক সময় দুটো রুট নোড ধরে না, বরং নির্দিষ্ট একটা এজ দিয়ে ট্রি জোড়া লাগাতে হয়। তারমানে একটা ট্রিকে রি-রুট করতে হবে (এজের প্রান্তকে নতুন রুট বানাতে হবে)।
প্রথম দেখায় মনে হবে রি-রুটিং খুব কস্টলি আর কমপ্লেক্সিটি অনেক বাড়িয়ে দেবে।
আসলে, ভার্টেক্স $v$-তে রি-রুট করতে $v$ থেকে পুরানো রুট পর্যন্ত যেতে হবে আর পাথের সব নোডে parent[] আর real_parent[] উল্টে দিতে হবে।
কিন্তু আসলে এত খারাপ না — আগের সেকশনের আইডিয়া মতো ছোট ট্রিকে রি-রুট করলে গড়ে $O(\log n)$ পাওয়া যায়।
বিস্তারিত (টাইম কমপ্লেক্সিটির প্রুফসহ) অনলাইনে ব্রিজ খোঁজা আর্টিকেলে পাবে।
ঐতিহাসিক পটভূমি#
DSU ডাটা স্ট্রাকচারটা বহু পুরানো।
ট্রির ফরেস্ট আকারে সংরক্ষণের এই পদ্ধতি সম্ভবত প্রথম দেখিয়েছিলেন Galler আর Fisher 1964 সালে (Galler, Fisher, “An Improved Equivalence Algorithm”), তবে টাইম কমপ্লেক্সিটির পুরো অ্যানালাইসিস অনেক পরে হয়েছিল।
পাথ কম্প্রেশন আর ইউনিয়ন বাই র্যাঙ্ক অপটিমাইজেশন McIlroy আর Morris বানিয়েছিলেন, আর তাদের থেকে আলাদাভাবে Tritter-ও করেছিলেন।
Hopcroft আর Ullman 1973 সালে $O(\log^\star n)$ টাইম কমপ্লেক্সিটি দেখান (Hopcroft, Ullman “Set-merging algorithms”) — এখানে $\log^\star$ হলো ইটারেটেড লগারিদম (ধীরে বাড়ে, কিন্তু ইনভার্স অ্যাকারম্যান ফাংশনের মতো ধীর না)।
$O(\alpha(n))$ বাউন্ড প্রথমবার 1975 সালে দেখানো হয়েছিল (Tarjan “Efficiency of a Good But Not Linear Set Union Algorithm”)। পরে 1985 সালে Tarjan, Leeuwen-এর সাথে মিলে বিভিন্ন র্যাঙ্ক হিউরিস্টিক আর পাথ কম্প্রেশনের জন্য একাধিক কমপ্লেক্সিটি অ্যানালাইসিস পাবলিশ করেন (Tarjan, Leeuwen “Worst-case Analysis of Set Union Algorithms”)।
সবশেষে 1989 সালে Fredman আর Sachs প্রুফ করেন যে এই কম্পিউটেশন মডেলে DSU সমস্যার যেকোনো অ্যালগরিদমকে গড়ে কমপক্ষে $O(\alpha(n))$ সময়ে কাজ করতে হবে (Fredman, Saks, “The cell probe complexity of dynamic data structures”)।