লোয়েস্ট কমন অ্যানসেস্টর (এলসিএ) - $O(\sqrt{N})$ এবং $O(\log N)$, $O(N)$ প্রিপ্রসেসিং সহ#
একটি ট্রি $G$ দেওয়া আছে। $(v_1, v_2)$ আকারের কুয়েরি দেওয়া আছে, প্রতিটি কুয়েরির জন্য লোয়েস্ট কমন অ্যানসেস্টর (বা লিস্ট কমন অ্যানসেস্টর) বের করতে হবে, অর্থাৎ এমন একটি ভার্টেক্স $v$ বের করতে হবে যেটি রুট থেকে $v_1$ পর্যন্ত পাথে এবং রুট থেকে $v_2$ পর্যন্ত পাথে অবস্থিত, এবং ভার্টেক্সটি সবচেয়ে নিচে হতে হবে। অন্যভাবে বলতে গেলে, কাঙ্ক্ষিত ভার্টেক্স $v$ হলো $v_1$ এবং $v_2$-এর সবচেয়ে নিচের অ্যানসেস্টর। এটা স্পষ্ট যে তাদের লোয়েস্ট কমন অ্যানসেস্টর $v_1$ এবং $v_2$-এর মধ্যকার শর্টেস্ট পাথে অবস্থিত। এছাড়াও, যদি $v_1$ হয় $v_2$-এর অ্যানসেস্টর, তাহলে $v_1$ হলো তাদের লোয়েস্ট কমন অ্যানসেস্টর।
অ্যালগরিদমের মূল ধারণা#
কুয়েরির উত্তর দেওয়ার আগে, আমাদের ট্রিটি প্রিপ্রসেস করতে হবে। আমরা রুট থেকে শুরু করে একটি DFS ট্রাভার্সাল চালাই এবং $\text{euler}$ নামে একটি লিস্ট তৈরি করি যেটি ভার্টেক্সগুলোর ভিজিটের ক্রম সংরক্ষণ করে (একটি ভার্টেক্স প্রথম ভিজিটের সময় লিস্টে যোগ হয়, এবং তার চিলড্রেনদের DFS ট্রাভার্সাল থেকে ফেরত আসার পরও যোগ হয়)। একে ট্রি-র অয়লার ট্যুরও বলা হয়। এটা স্পষ্ট যে এই লিস্টের আকার হবে $O(N)$। আমাদের আরো একটি অ্যারে $\text{first}[0..N-1]$ তৈরি করতে হবে যেটি প্রতিটি ভার্টেক্স $i$-এর $\text{euler}$-এ প্রথম উপস্থিতির অবস্থান সংরক্ষণ করে। অর্থাৎ, $\text{euler}$-এ প্রথম অবস্থান যেখানে $\text{euler}[\text{first}[i]] = i$। এছাড়াও DFS ব্যবহার করে আমরা প্রতিটি নোডের উচ্চতা (রুট থেকে দূরত্ব) বের করে $\text{height}[0..N-1]$ অ্যারেতে সংরক্ষণ করতে পারি।
তাহলে অয়লার ট্যুর এবং অতিরিক্ত দুটি অ্যারে ব্যবহার করে কীভাবে কুয়েরির উত্তর দেওয়া যায়? ধরি কুয়েরিটি হলো $v_1$ এবং $v_2$-এর একটি জোড়া। অয়লার ট্যুরে $v_1$-এর প্রথম ভিজিট এবং $v_2$-এর প্রথম ভিজিটের মধ্যে যে ভার্টেক্সগুলো আমরা ভিজিট করি তাদের বিবেচনা করি। সহজেই দেখা যায় যে, $\text{LCA}(v_1, v_2)$ হলো এই পাথে সবচেয়ে কম উচ্চতার ভার্টেক্স। আমরা ইতোমধ্যে লক্ষ্য করেছি যে, এলসিএ অবশ্যই $v_1$ এবং $v_2$-এর মধ্যকার শর্টেস্ট পাথের অংশ হবে। স্পষ্টতই এটি সবচেয়ে কম উচ্চতার ভার্টেক্সও হবে। এবং অয়লার ট্যুরে আমরা মূলত শর্টেস্ট পাথটিই ব্যবহার করি, তবে অতিরিক্তভাবে পাথের মধ্যে পাওয়া সব সাবট্রিও ভিজিট করি। কিন্তু এই সাবট্রিগুলোর সব ভার্টেক্স এলসিএ-র চেয়ে নিচে অবস্থিত এবং তাই তাদের উচ্চতা বেশি। সুতরাং $\text{LCA}(v_1, v_2)$ অনন্যভাবে নির্ধারণ করা যায় অয়লার ট্যুরে $\text{first}(v_1)$ এবং $\text{first}(v_2)$-এর মধ্যে সবচেয়ে কম উচ্চতার ভার্টেক্স খুঁজে।
আসুন এই ধারণাটি চিত্রিত করি। নিচের গ্রাফ এবং সংশ্লিষ্ট উচ্চতাসহ অয়লার ট্যুর বিবেচনা করুন:
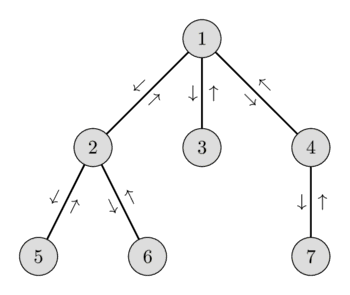
ভার্টেক্স $6$ থেকে শুরু হয়ে $4$-এ শেষ হওয়া ট্যুরে আমরা ভার্টেক্স $[6, 2, 1, 3, 1, 4]$ ভিজিট করি। এই ভার্টেক্সগুলোর মধ্যে ভার্টেক্স $1$-এর উচ্চতা সবচেয়ে কম, তাই $\text{LCA(6, 4) = 1}$।
সংক্ষেপে: একটি কুয়েরির উত্তর দিতে আমাদের শুধু $\text{euler}$ অ্যারেতে $\text{first}[v_1]$ থেকে $\text{first}[v_2]$ রেঞ্জে সবচেয়ে কম উচ্চতার ভার্টেক্স খুঁজতে হবে। এভাবে, এলসিএ সমস্যাটি আরএমকিউ সমস্যায় রিডিউস হয়ে যায় (একটি রেঞ্জে মিনিমাম বের করার সমস্যা)।
Sqrt-ডিকম্পোজিশন ব্যবহার করে, প্রতিটি কুয়েরির উত্তর $O(\sqrt{N})$-এ এবং প্রিপ্রসেসিং $O(N)$ সময়ে পাওয়া সম্ভব।
একটি সেগমেন্ট ট্রি ব্যবহার করে প্রতিটি কুয়েরির উত্তর $O(\log N)$-এ এবং প্রিপ্রসেসিং $O(N)$ সময়ে দেওয়া যায়।
যেহেতু সংরক্ষিত মানগুলোতে আপডেট প্রায় কখনোই হবে না, তাই স্পার্স টেবিল একটি ভালো পছন্দ হতে পারে, যেটি $O(N\log N)$ বিল্ড সময়ে $O(1)$ কুয়েরি উত্তর দিতে পারে।
ইমপ্লিমেন্টেশন#
এলসিএ অ্যালগরিদমের নিম্নলিখিত ইমপ্লিমেন্টেশনে একটি সেগমেন্ট ট্রি ব্যবহার করা হয়েছে।
struct LCA {
vector<int> height, euler, first, segtree;
vector<bool> visited;
int n;
LCA(vector<vector<int>> &adj, int root = 0) {
n = adj.size();
height.resize(n);
first.resize(n);
euler.reserve(n * 2);
visited.assign(n, false);
dfs(adj, root);
int m = euler.size();
segtree.resize(m * 4);
build(1, 0, m - 1);
}
void dfs(vector<vector<int>> &adj, int node, int h = 0) {
visited[node] = true;
height[node] = h;
first[node] = euler.size();
euler.push_back(node);
for (auto to : adj[node]) {
if (!visited[to]) {
dfs(adj, to, h + 1);
euler.push_back(node);
}
}
}
void build(int node, int b, int e) {
if (b == e) {
segtree[node] = euler[b];
} else {
int mid = (b + e) / 2;
build(node << 1, b, mid);
build(node << 1 | 1, mid + 1, e);
int l = segtree[node << 1], r = segtree[node << 1 | 1];
segtree[node] = (height[l] < height[r]) ? l : r;
}
}
int query(int node, int b, int e, int L, int R) {
if (b > R || e < L)
return -1;
if (b >= L && e <= R)
return segtree[node];
int mid = (b + e) >> 1;
int left = query(node << 1, b, mid, L, R);
int right = query(node << 1 | 1, mid + 1, e, L, R);
if (left == -1) return right;
if (right == -1) return left;
return height[left] < height[right] ? left : right;
}
int lca(int u, int v) {
int left = first[u], right = first[v];
if (left > right)
swap(left, right);
return query(1, 0, euler.size() - 1, left, right);
}
};অনুশীলন সমস্যা#
- SPOJ: LCA
- SPOJ: DISQUERY
- TIMUS: 1471. Distance in the Tree
- CODEFORCES: Design Tutorial: Inverse the Problem
- CODECHEF: Lowest Common Ancestor
- SPOJ - Lowest Common Ancestor
- SPOJ - Ada and Orange Tree
- DevSkill - Motoku (archived)
- UVA 12655 - Trucks
- Codechef - Pishty and Tree
- UVA - 12533 - Joining Couples
- Codechef - So close yet So Far
- Codeforces - Drivers Dissatisfaction
- UVA 11354 - Bond
- SPOJ - Querry on a tree II
- Codeforces - Best Edge Weight
- Codeforces - Misha, Grisha and Underground
- SPOJ - Nlogonian Tickets
- Codeforces - Rowena Rawenclaws Diadem